Last week, Mona Chalabi wrote an interesting post on car crash statistics by state, at fivethirtyeight.com.
I didn’t like the figures so much, though. There were a number of them like this:
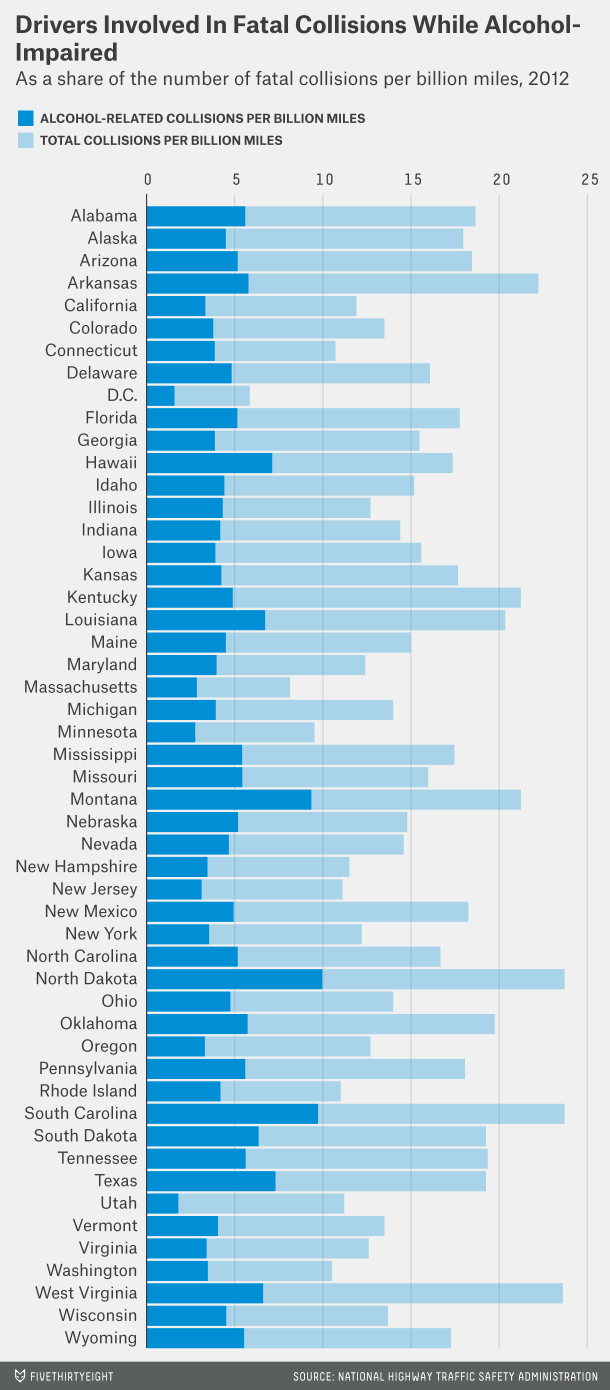
I’m giving a talk today about data visualization [slides | github], and I thought this would make a good example, so I spent some time creating versions that I like better.
There are two basic issues with Mona Chalabi’s graphs. First, you almost never want to use alphabetical order. It’s useful for finding particular states, but it’s not useful for anything else. (Howard Wainer calls this “Austria first!” See, e.g., this paper.) If you order the states by one of the variables (e.g., by the total collisions per billion miles), you can better identify important patterns.
Second, the separate figures make comparisons difficult. It would be better to put everything side-by-side. Even better is to do some scatterplots.
(We shouldn’t be too hard on Mona Chalabi, though. Yesterday she tweeted a great illustration of the suckiness of pie charts, which I’m also using as an example in my lecture today.)
Dot plots
I started with a set of side-by-side dot plots, with states ordered by total collisions per billion miles:
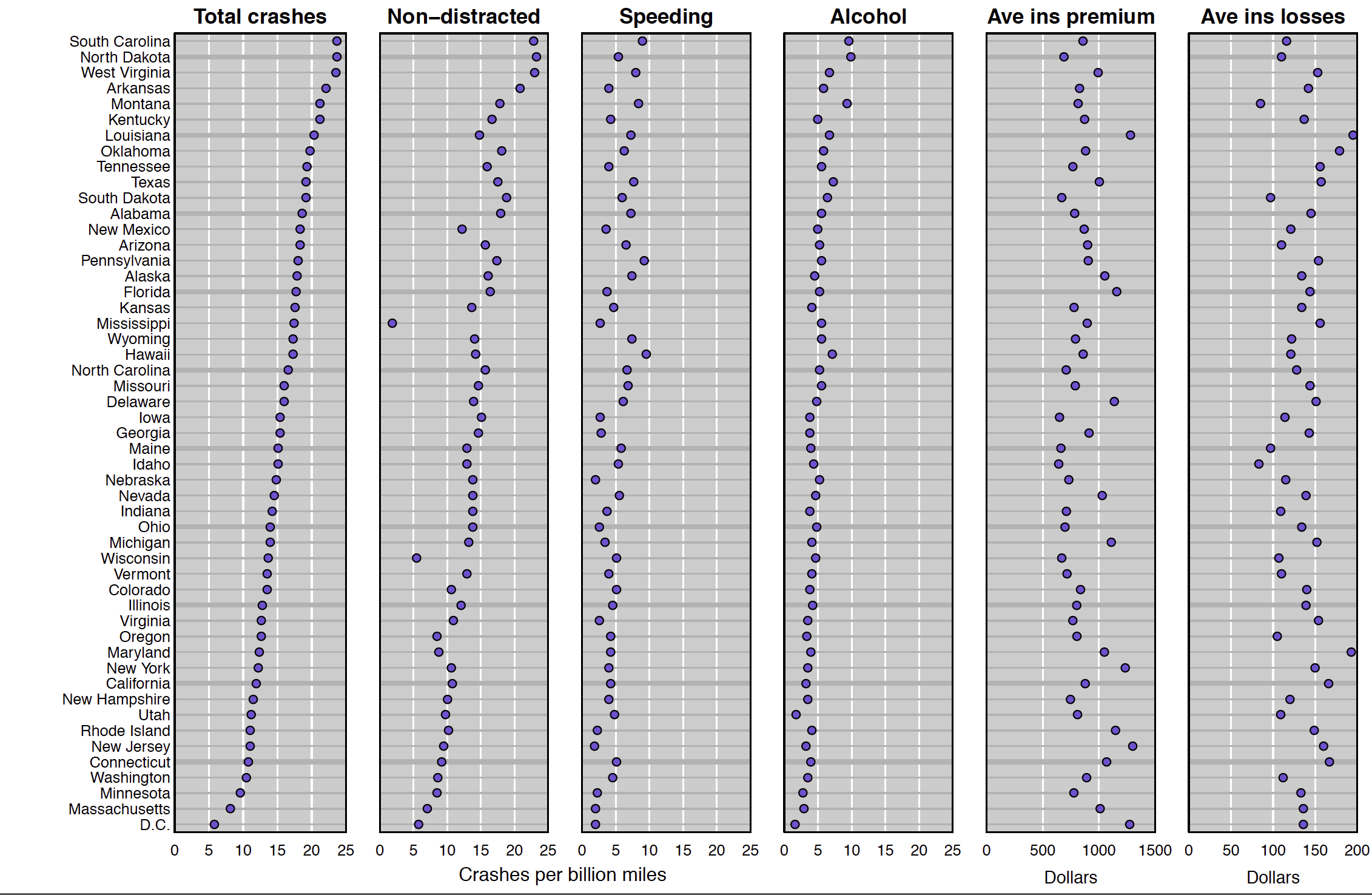
The design was inspired by the figures in Visualizing data patterns with micromaps (Carr and Pickle, 2010). (I’m a huge Dan Carr fan.)
Sorting the states by the first variable allows you to more easily pick out the states with the highest (and lowest) rates of car crashes. (Note that these are just car crashes with fatalities.) And you can more easily see the associations among the different variables.
Scatterplots
If you’re interested in the associations among the variables, it’s best to look at scatterplots. Here are what I viewed to be the most interesting ones:
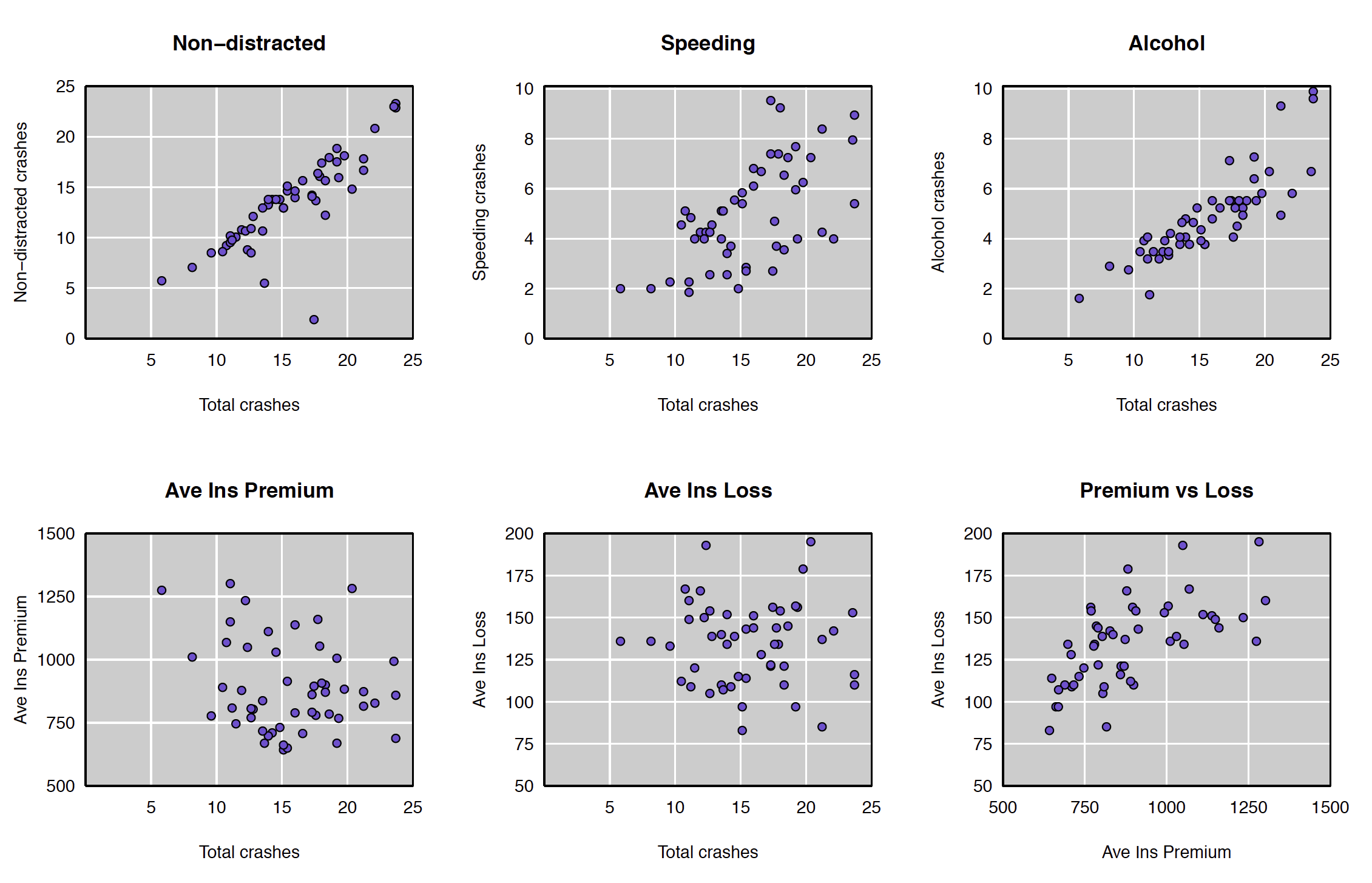
The association between average insurance premiums and average insurance losses is now clear. And there’s an interesting pattern in the association between speeding-related crashes and total crashes. It’s like there are two groups of states: those with low speeding-related crashes and those with high speeding-related crashes.
You can’t identify the states in this graph; it would be far better if it were interactive (ideally, linked to the dot chart and allowing brushing).
The data
It was a bit of a pain to get the data to make the revised plots. The National Highway Traffic Safety Administration has a lot of data, but I didn’t want to spend the time trying to make sense of it and extract the numbers.
I considered trying to do some image analysis to figure out the lengths of the bars in the bar plots, but I don’t have much experience with that, so while it’d be a great thing to learn, it seemed like I wouldn’t be able to get it done in time.
So I used the old-fashioned method: print the graphs and measure the bars with a ruler. Here’s a scan of some of my measurements (click on it to see the larger version).
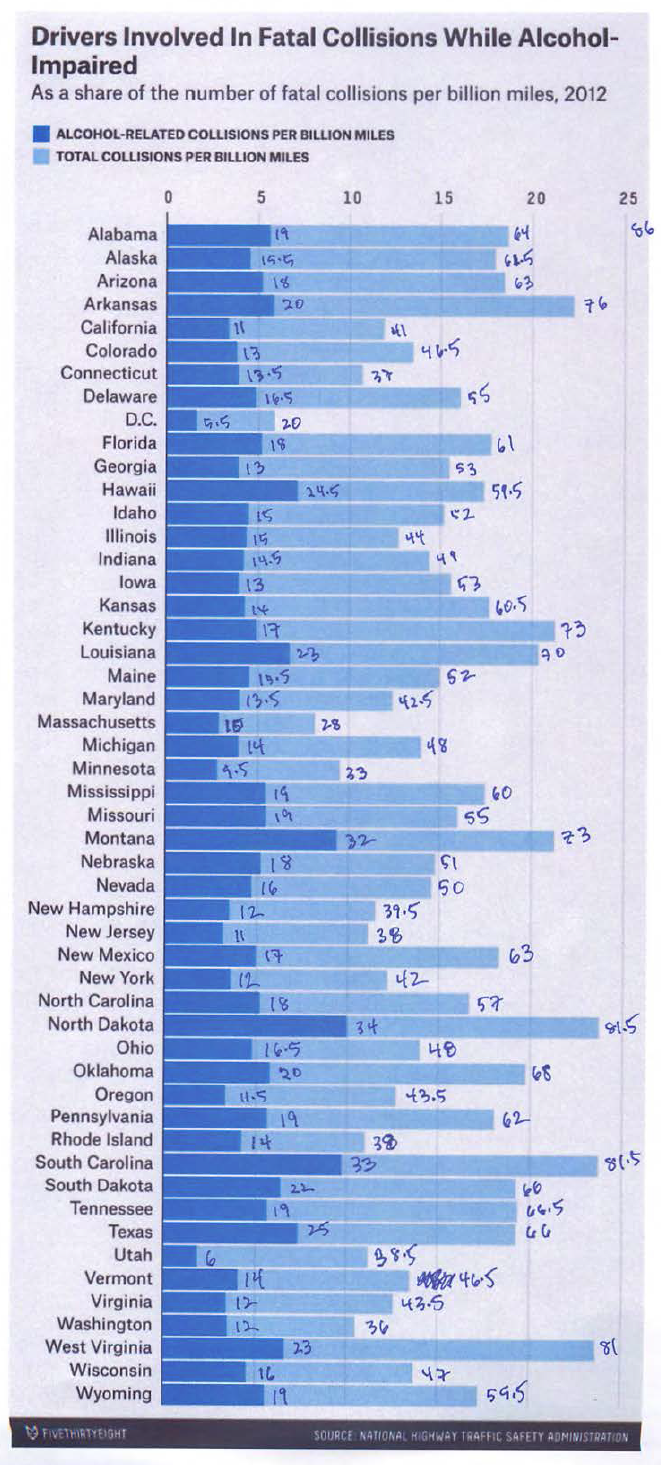
Data entry was another not-quite-how-I-want-my-scientific-collaborators-to-be-doing-this aspect. The data are here, as R code, in the most tedious possible form. And surely there are errors.
The code
The code to make the dotplots is here; the code to make the scatterplots is here. Not the prettiest, and uses base graphics not the recommended ggplot2, and with the grayplot function in my R/broman package.
Update
Mona Chalabi and Andrew Flowers posted the data at github.com/fivethirtyeight/data. I discuss the errors in my ruler-based measurements here.